

אמת מידה חדשה מראה שאין די בעמידה בבדיקות רפואיות; סוכני בינה מלאכותית קלינית חייבים לאסוף מידע, לטפל באי ודאות, להשתמש בכלים, לפרש תמונות ולנווט הטיה במפגשי חולים מדומים.
הפעלת סוכני שפה ב- AgentClinic. (משמאל) דיאגרמת זרימת עבודה של סוכנים ב- AgentClinic. סוכן הרופא מקיים אינטראקציה עם כלים וסוכנים על מנת להגיע לאבחנה. סוכן מנחה משווה את המסקנה לאבחון האמת הבסיסית בסוף הסימולציה. (מימין) דוגמה לדיאלוג בין סוכנים ב-benchmark של AgentClinic.
מחקר שפורסם לאחרונה בכתב העת npj רפואה דיגיטלית הציגה רף סוכן רב-מודאלי, AgentClinic, לבינה מלאכותית קלינית (AI) סוכנים בסביבות קליניות מדומות.
בניית מערכות אינטראקטיביות המסוגלות לפתור מגוון רחב של בעיות היא אחת המטרות העיקריות של AI. דגמי שפות גדולים אחרונים רבים (לימודי תואר שני) פתרו בעיות קשות, חלקן מאתגרות אפילו עבור בני אדם, וגם עלו על הציון האנושי הממוצע בבדיקות רישוי רפואי. עם זאת, מספר מגבלות מונעות את יישומם במסגרות קליניות בעולם האמיתי.
העבודה הקלינית משולבת, הכוללת קבלת החלטות רציפה הדורשת טיפול באי ודאות עם משאבים סופיים ומידע מוגבל. יכולת זו אינה באה לידי ביטוי בהערכות נוכחיות, שבהן כל הנתונים הדרושים מוצגים במקרה של וינייטות ו לימודי תואר שני מוטלת עליהם משימה לענות או לבחור באפשרות הסבירה ביותר.
הכותבים ציינו שביצועים חזקים במשימות תשובות לשאלות רפואיות סטטיות היו רק ניבוי חלש של ביצועים בסביבה האינטראקטיבית של AgentClinic. במקרים מסוימים, דיוק האבחון ירד בחדות כאשר מקרים סטטיים הומרו לפורמט הרציף של AgentClinic.
עיצוב מחקר של AgentClinic ומבנה בנצ'מרק
במחקר הנוכחי, החוקרים הציגו את AgentClinic, אמת מידה לסוכן רב-מודאלי עבור LLM הערכה במסגרות קליניות מדומה. המדד כלל ארבעה סוכני שפה: סוכן מדידה, סוכן רופא, סוכן מטופל ומנחה. לכל סוכן יש הנחיות ספציפיות והוא מסופק עם מידע ייחודי שאינו זמין לסוכנים אחרים. סוכן הרופא הוא המודל שביצועיו מוערכים על ידי סוכנים אחרים.
שאלות ממערך הנתונים של MedQA המבוסס על מקרים בסגנון בחינת הרישוי הרפואי של ארצות הברית, New England Journal of Medicine (NEJM) אתגרי מקרה, וביטול זיהוי MIMIC-IV רשומות בריאות אלקטרוניות שימשו לבניית סוכנים המבוססים על תרחישים רלוונטיים מבחינה רפואית. השאלות עסקו באבחון המבוסס על סימפטומים, ששימשו לבניית תבנית להנחיות. עבור AgentClinic-MIMIC-IV ו-AgentClinic-MedQA, שאלות נבחרו מתוך MIMIC-IV ו-MedQA מערכי נתונים, בהתאמה.
קובץ קלט מובנה המכיל מידע על מקרה נוצר באמצעות GPT-4, ותרחישי המקרים אומתו ידנית. באופן כללי, לסוכן הרופא ניתנה מטרה; סוכן המטופל קיבל את הסימפטומים וההיסטוריה של המטופל; גורם המדידה קיבל את תוצאות הבדיקה הגופנית; והמנחה קיבל את האבחנה הנכונה. הדיוק של 11 לימודי תואר שני הוערך ב- AgentClinic-MedQA, כאשר כל אחד מהם פעל כסוכן הרופא לאבחן את סוכן המטופל (GPT-4) באמצעות דיאלוג.
20 אינטראקציות הותרו לסוכן הרופא עם המטופל וסוכני מדידה לפני ביצוע אבחנה. בנוסף, הביצועים של שלושה רופאים אנושיים הוערכו תוך שימוש באותם אילוצים והוראות, אם כי יש לפרש את המדגם הקטן הזה של רופאים. קלוד 3.5 סונט הפגין את הדיוק הגבוה ביותר של 62.1%, ואחריו OpenBioLLM-70B (58.3%) ורופאים (54%).
ביצועי AgentClinic על פני מודלים, כלים ואופנים
יתר על כן, הדיוק ב- AgentClinic-MIMIC-IV היה הגבוה ביותר עבור קלוד 3.5 סונט (42.9%), ואחריו GPT-4 (34%) ו-GPT-3.5 (27.5%). הפחתת מספר האינטראקציות ל-10 הורידה משמעותית את הדיוק ל-25%, בעוד שהגדלתו ל-30 אינטראקציות גם הורידה את הדיוק. הדיוק של סוכן הרופא השתנה לפי סוכן המטופל; סוכני מטופלים מסוג GPT-4 השיגו דיוק גבוה יותר מתרופות ממשפחת Mixtral-8x7B או GPT-3.5.
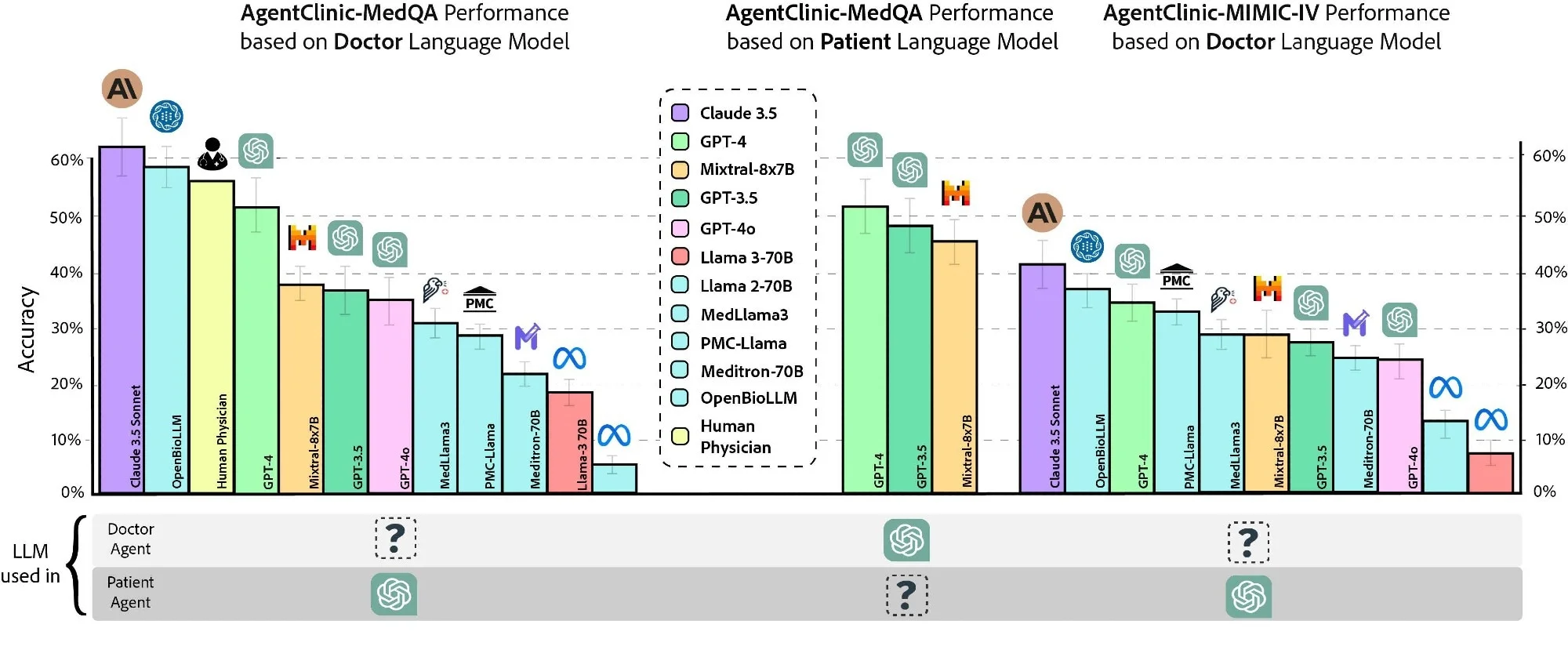
דיוק של מודלים שונים של שפת רופא ורופאים אנושיים על AgentClinic-MedQA באמצעות GPT-4 חולים וחומרי מדידה (משמאל). דיוק של GPT-4 על AgentClinic-MedQA מבוסס על מודל שפת המטופל (באמצע). דיוק ב- AgentClinic-MIMIC-IV לפי מספר השימוש ב-GPT-4 מטופל וחומרי מדידה (מימין).
לאחר מכן, החוקרים העריכו את ההשפעה של שישה כלי סוכן על דיוק האבחון: שרשרת השתקפות של מחשבה (CoT), מחברת, Zero-Shot CoTGeneration Augmented Retrieval Adaptive באמצעות מקורות ספרי לימוד, Generation Augmented Retrieval Adaptive באמצעות מקורות אינטרנט ו-One-Shot CoT. קלוד 3.5 Sonnet הפגין את הביצועים הטובים ביותר עם דיוק ממוצע ושיא של 51.3% ו-56.1%, בהתאמה, עם הכלי Notebook. GPT-4o ו-GPT-4 זכו לשיפורים מתונים ברוב הכלים, אך השימוש בכלים לא היה מועיל באופן אחיד בכל הדגמים.
יתר על כן, הטיות מרומזות (אסוציאציות לא מודעות המושפעות מנורמות תרבותיות וחברתיות, כגון הטיה מגדרית) והטיות קוגניטיביות (דפוסים שיטתיים של סטייה מרציונליות או נורמות בשיפוט, למשל הטיית עדכניות) נכללו בהנחיות להערכת השפעותיהן על דיוק האבחון. עבור GPT-4, הדיוק ירד ל-48% ו-50.3% עבור הטיות קוגניטיביות של מטופל ורופא ול-51.3% ו-50.5% עבור הטיות מרומזות של מטופל ורופא, בהתאמה. המדד גם העריך ביטחון מדומה של המטופל, היענות לטיפול, ונכונות להתייעץ שוב עם אותו רופא, אך דירוגים אלה הגיעו מ LLMחולים מדומים ולא חולים אמיתיים.
לאחר מכן, הצוות בחן מקרים של מומחים תוך שימוש בשאלות דוחות מקרה המשתרעות על תשע התמחויות רפואיות ממערך הנתונים של MedMCQA. באופן עקבי, קלוד 3.5 סונט היה המודל בעל הביצועים הטובים ביותר, עם דיוק אבחון ממוצע של 66.7%, והפגין ביצועים חזקים ברפואה פנימית, אף-אוזן-גרון וגינקולוגיה. הביצועים השתנו לפי התמחות, מה שמצביע על כך שאבחון מבוסס דיאלוג עשוי להיות שונה מבדיקות רפואיות רב-ברירות סטטיות. לאחר מכן, הצוות העריך ארבעה רב-מודלים לימודי תואר שני בהגדרת אבחון שדרשה בנוסף הבנת קריאות תמונה.
החוקרים גם העריכו מקרים רב לשוניים בשבע שפות: אנגלית, סינית, צרפתית, ספרדית, הינדית, פרסית וקוריאנית. רוב הדגמים הציגו את הביצועים הטובים ביותר באנגלית והראו שונות משמעותית בשפות אחרות, בעוד שקלוד 3.5 Sonnet שמר על הביצועים הכוללים הרב-לשוניים החזקים ביותר.
לשם כך, 120 שאלות מה- NEJM נעשה שימוש באתגרי מקרה. כאשר התמונה סופקה לראשונה לסוכן הרופא, לקלוד 3.5 סונט היה דיוק אבחוני של 37.2%, ואחריו GPT-4 (27.7%), GPT-4o (21.4%) ו-GPT-4o-mini (8%). כאשר התמונות סופקו לפי בקשה על ידי הסוכן, הדיוק היה 35.4%, 25.4%, 19.1% ו-6.1% עבור קלוד 3.5 Sonnet, GPT-4, GPT-4o ו-GPT-4o-mini, בהתאמה.
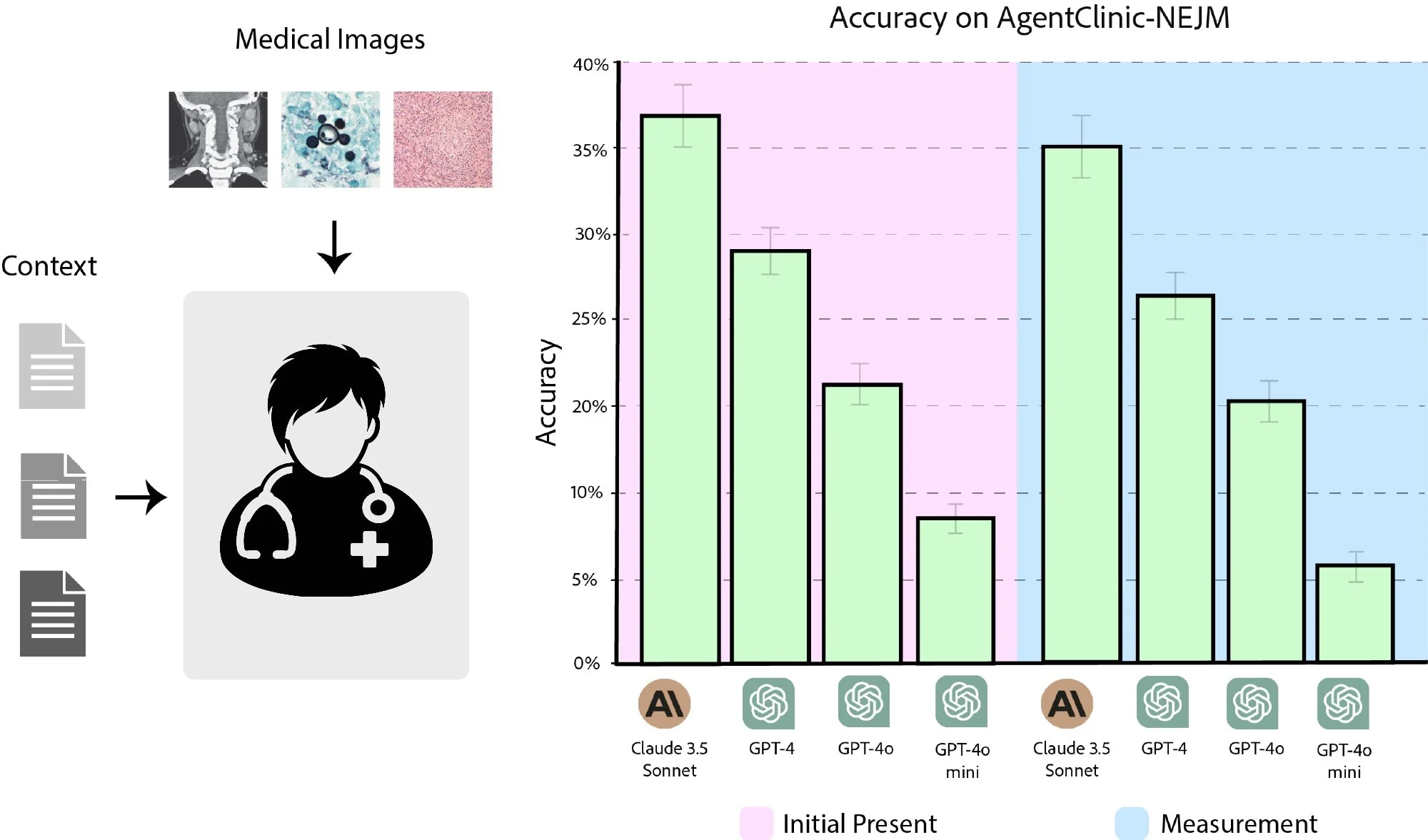
דיוק של קלוד 3.5 Sonnet, GPT-4, GPT-4o ו-GPT-4o-mini ב- AgentClinic-NEJM עם קלט רב-מודאלי של טקסט ושפה. (ורוד) דיוק כאשר התמונות מוצגות כקלט ראשוני. (כחול) דיוק כאשר יש לבקש תמונות מקורא התמונות.
השלכות AgentClinic להערכת AI קלינית
יַחַד, לימודי תואר שני צריך להעריך באמצעות אסטרטגיות חדשות מעבר לאמות מידה סטטיות של שאלות ותשובות. AgentClinic, המספקת סביבה קלינית פשוטה הכוללת סוכנים המייצגים מנחה, מטופל, רופא ומדידות, מייצגת צעד לקראת בניית אמות מידה מונעות דיאלוג, אינטראקטיביות יותר שמעריכות את יכולת קבלת ההחלטות ברצף של לימודי תואר שני על פני הגדרות מובחנות, רב-מודאליות ומאתגרות. עם זאת, הכותבים הזהירו כי AgentClinic נותרה סימולציה פשוטה של טיפול קליני, באמצעות LLMסוכני מטופל, מדידה ומנחה מבוססי. הם גם ציינו סיכוני דליפת נתונים פוטנציאליים עבור מודלים קנייניים והדגישו שנתוני ההשוואה בין בני אדם הגיעו משלושה רופאים בלבד.
לפיכך יש לפרש ממצאים אלה כביצועי אמת מידה, ולא עדות לכך שמודל כלשהו מוכן לאבחון קליני אוטונומי.
דירגנו בינה מלאכותית רפואית כאילו היא עוברת מבחן רב-ברירה. אבל הרפואה בעצם לא עובדת ככה.
מאמר חדש של npj Digital Medicine מציג את AgentClinic: אמת מידה שבה סוכני בינה מלאכותית חייבים לראיין מטופלים, לאסוף מידע חסר, לפרש מולטי-מודאלי… pic.twitter.com/BrS2yXJ4PL
– npj Digital Medicine (@npjDigitalMed) 29 באפריל, 2026

