

עולמו של AI הוא תחרותי. תיאורטית, מרבית דגמי ה- AI העיקריים ששמעת עליהם הם ברמה דומה. כולם מציעים חבילות ותכונות דומות למדי עם מעט הבדלים בולטים על פני השטח.
עם זאת, כשאתה חופר קצת יותר עמוק, כולם קיימים בקנה מידה. דגמי AI נבדקים כל העת ומוצגים. אלה יכולים להיות מבחנים של האינטליגנציה הרגשית שלהם, יכולת הקידוד, כישורי הכתיבה או אפילו סתם יכולתם לעבד מבחני היגיון.
זה המקום בו, בעולם של שוליים קטנים, לדגמים אלה יש אפשרות לצאת למעלה. במשך החודשים האחרונים שלטו תאומים של גוגל את מרבית המבחנים הללו, ואז גרוק של קסאי נכנס לעדכון להתאמה של תאומים.
עכשיו, GPT-5 כאן. במשך חודשים, אלטמן וצוותו העלו זאת כעדכון מגדיר בתעשייה. אז, עכשיו כשהוא הגיע, האם זה באמת נכון?

בהתחלה, Openai הראתה את מדד משלה. זה הראה מה כולם ציפו: שדרוג גדול בכל אזור בודד. למעט, כפי שדיווחה על ידי ה- verge, הגרפים לא היו בדיוק מדויקים.
כן, המספרים צדקו, אבל גרפי העמודות ששימשו גרמו ל- Openai להיראות כאילו היה קילומטרים קדימה. במבט מקרוב את המספרים, זה היה קרוב יותר ליתרון קל.
כעת, העומד לרשות הציבור, GPT-5 הועבר דרך מדדים חיצוניים הנפרדים מ- OpenAI. ככה זה באמת קלע.
כיצד קלע GPT-5 במבחני מדד
Vellum
בדיקות אלה יכולות לנוע בהערכות שלהם. הם יכולים להיות כרוכים בשאלת דגמי AI שאלות מרובות בחירה, לגרום להם לפתור חידות, או פשוט לנתח את התצורות שמאחורי הקלעים.
Vellum, חברת AI Bencharking, בודקת דגמים במגוון רחב של אזורים. ב- LLM Leaderboard של החברה, GPT-5 תופס את המקום הראשון הן בהנמקה (הבנתו בביולוגיה, פיזיקה וכימיה), כאשר גרוק 4 קלע רק 2% מתחתיו ומאחוריו של תאומים 3%.
GPT-5 מוביל גם את הטבלה ביכולת המתמטיקה בתיכון, עם שני דגמים אחרים של OpenAI עוקבים אחריו. זה הגיע למקום השני אחרי גרוק 4 ביכולת קידוד (אך רק ב- 0.1%).
עם זאת, זה לא היה נראה בשום מקום במבחנים של הנמקה אדפטיבית (עד כמה מודל מתאים למושגים חדשים במקום להסתמך על דפוסים שנלמדו מראש)-מיומנות שקלוד תאומים ואנתרופי הוביל הלאה.
ניתוח מלאכותי
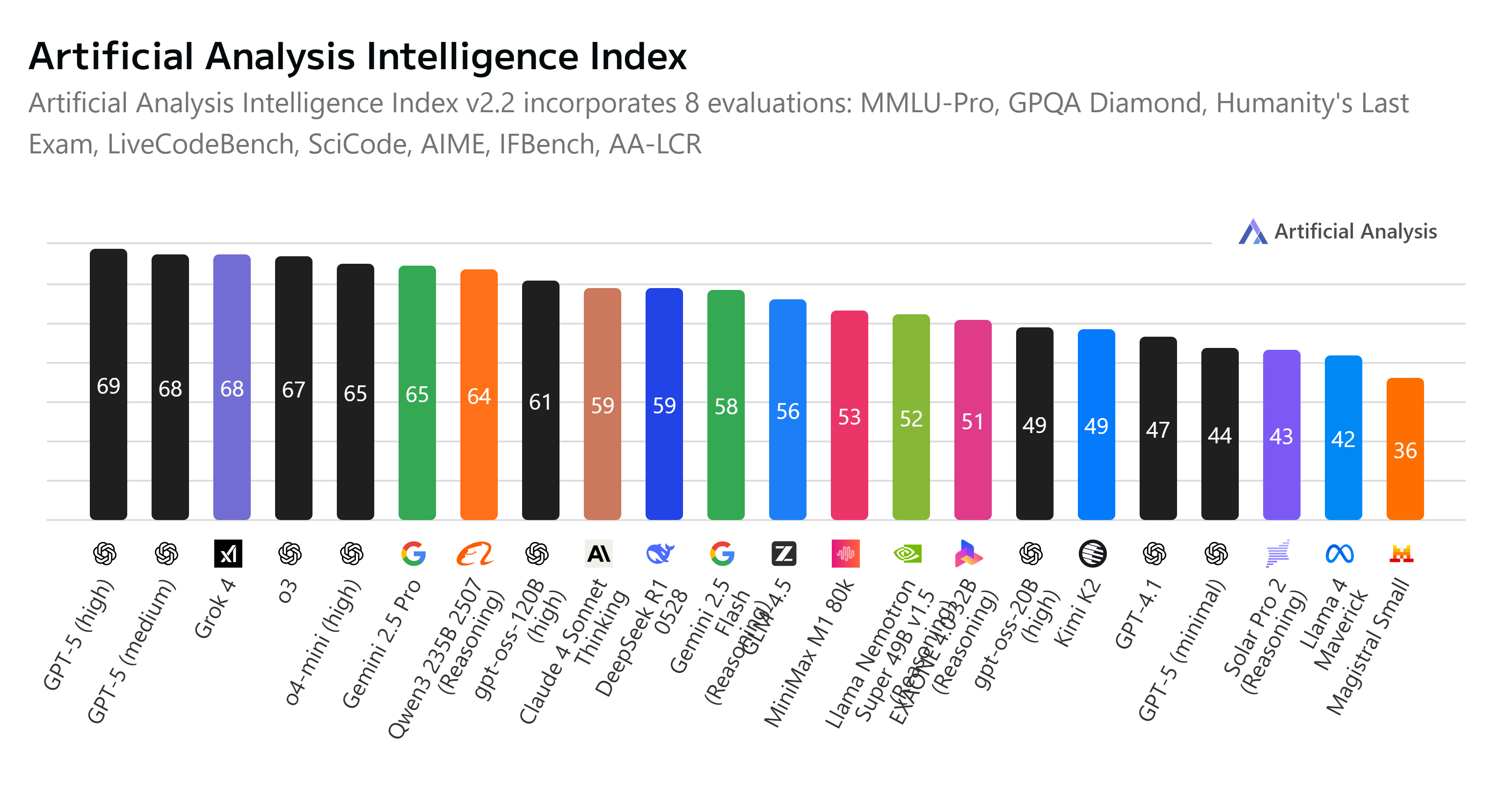
Leaderboard פופולרי נוסף של AI Bencharking מגיע מניתוח מלאכותי. לוח הדירוג בוחן דגמים על מדדי מפתח כולל אינטליגנציה, מחיר, ביצועים ומהירות.
בשיטת בדיקה זו, GPT-5 לוקח את שני המקומות המובילים, עם דגמי המאמץ והמאמץ הבינוני הגבוה שלה. GPT-5 רק מגרד את Grok 4 במדד למודיעין מודל, קלע 69 (גרוק 4 קלע 68).
LMARENA
Lmarena בוחן דגמים במגוון רחב של קטגוריות. אלה מתמקדים ביכולת הדור של הדגם עם טקסט, קוד, תמונות, וידאו ועוד.
הדירוג נובע משילוב של קולות מהבדיקה הציבורית והבית. GPT-5 הגיע הראשון לטקסט, קידוד ויכולתו להבין ולעבד תשומות חזותיות.
GPT-5 היה גם מודל ה- AI מספר אחת בזירת החברה. זה המקום בו מאות דגמי AI מתחרים בקידוד, מתמטיקה, כתיבה יצירתית, הדרכה להלן ועוד.
GPT-5 הוביל בכל הקטגוריות הללו במבחני החברה, והכה את קלוד ובמיני האנתרופית בתפקידים הבאים.
Livebench

זהו אחד המבחנים הידועים יותר עבור AI. LiveBench כולל קבוצה של 21 משימות מגוונות על פני 7 קטגוריות. לכל שאלה שנשאלת יש תשובות אובייקטיביות ניתנות לאמת. זה מסיר את הסיכונים לשונות עם תשובות ברורות הדרושות.
GPT-5 לוקח כיום את שלושת המקומות הראשונים בלוח המובילים דרך גרסאותיו הגבוהות, הבינוניות והנמוכות. ל- GPT-5 High היה הציון הגבוה ביותר בהנמקה, קידוד וקידוד סוכן. זה גם הוביל עם מוביל משמעותי במתמטיקה ובשפה.
SimpleBench
לקראת ההשקה של GPT-5, היו שמועות כי העדכון יהיה מודל ה- AI הראשון שיכה את קו הבסיס האנושי ב- SimpleBench.
זהו מדד טקסט מרובה בחירות עבור AI. אנשים עם ידע ברמת התיכון נשאלו למעלה מ -200 שאלות המכסים הנמקה מרחבית-זמנית, אינטליגנציה חברתית ושאלות טריק.
אף מודל AI לא הצליח לנצח את הממוצע האנושי במבחן זה. אז מה עם GPT-5? לא רק שזה לא ניצח את הממוצע האנושי של 83.7%, אלא שהוא למעשה הגיע במקום החמישי, ונפל מאחורי Gemini 2.5 Pro, Grok 4 ושני דגמי קלוד 4.
האם GPT-5 עומד בהייפ?
אנחנו עדיין מוקדמים בחיי GPT-5. על פי המבחנים המוקדמים הללו, העדכון האחרון של OpenAI מוביל את האישום ברוב המכריע של האזורים. עם זאת, ראוי לציין כי למרות שהוא בראש לוחות המנהיגים, זה רק בהפרש קטן.
ברוב האזורים, GPT-5 מוביל באחוז קטן, ובמקרים מסוימים זה מנצח כשמסתכלים על כל הגורמים. זה לא אומר בהכרח שזו האפשרות הטובה ביותר בכל המצבים אלא בסך הכל הטוב ביותר.
ישנן גם המון בדיקות מדד אחרות שעליהן צריך לבדוק את המודל. במהלך החודשים הקרובים נראה כיצד GPT-5 נמתח נגד התחרות על פני מגוון רחב של מיומנויות ומבחנים.
עם זאת, לעת עתה, נראה כי ל- GPT-5 יש את ההובלה, במיוחד באזורים שבהם GPT-5 ראו את העדכונים הגדולים ביותר. זה כולל כתיבה יצירתית, קידוד ושאלות מבוססות בריאות.

