

ChatGPT יכול לרמות אנשים לחשוב שזה בן אדם, אבל רק אם הוא 'מתנהג מטומטם' קודם. לפחות זה אחד הממצאים של מחקר שנערך לאחרונה על האם מודלים של AI יכולים לעבור את מבחן טיורינג.
שרבל-רפאל סגרי, מנכ"לית ה-Centre pour la Sécurité de l'IA (CeSIA) הדגישה את הנחיית 'השתוללות' ב-X. היא פורסמה במאמר מחקר טרום-דפוס על ידי מומחים מאוניברסיטת סן דייגו.
במבחן טיורינג, שהוצע לראשונה על ידי המתמטיקאי המפורסם אלן טיורינג, צד שלישי מנהל שיחה עם בינה מלאכותית ועם אדם ומחליט מיהו האדם. במבחן המתוקן הזה זו לא הייתה שיחה משולשת, אלא סדרה של אחד על אחד.
שופטים אנושיים זיהו בני אדם אמיתיים ב-67% מהמקרים ו-ChatGPT המריץ את GPT-4 כבני אדם ב-54% מהמקרים, וניצחו סטטיסטית את מבחן טיורינג.
עם זאת, הצוות היה צריך תחילה להורות ל-ChatGPT לאמץ את הפרסונה של מישהו המשתמש בסלנג ועושה שגיאות כתיב. עם שדרוגים פוטנציאליים שיגיעו ל-ChatGPT בעתיד, הבינה המלאכותית עשויה להיות מסוגלת להבין מה הוא צריך כדי 'להטפשף' בעצמו.
איך החוקרים בדקו עבור בני אדם
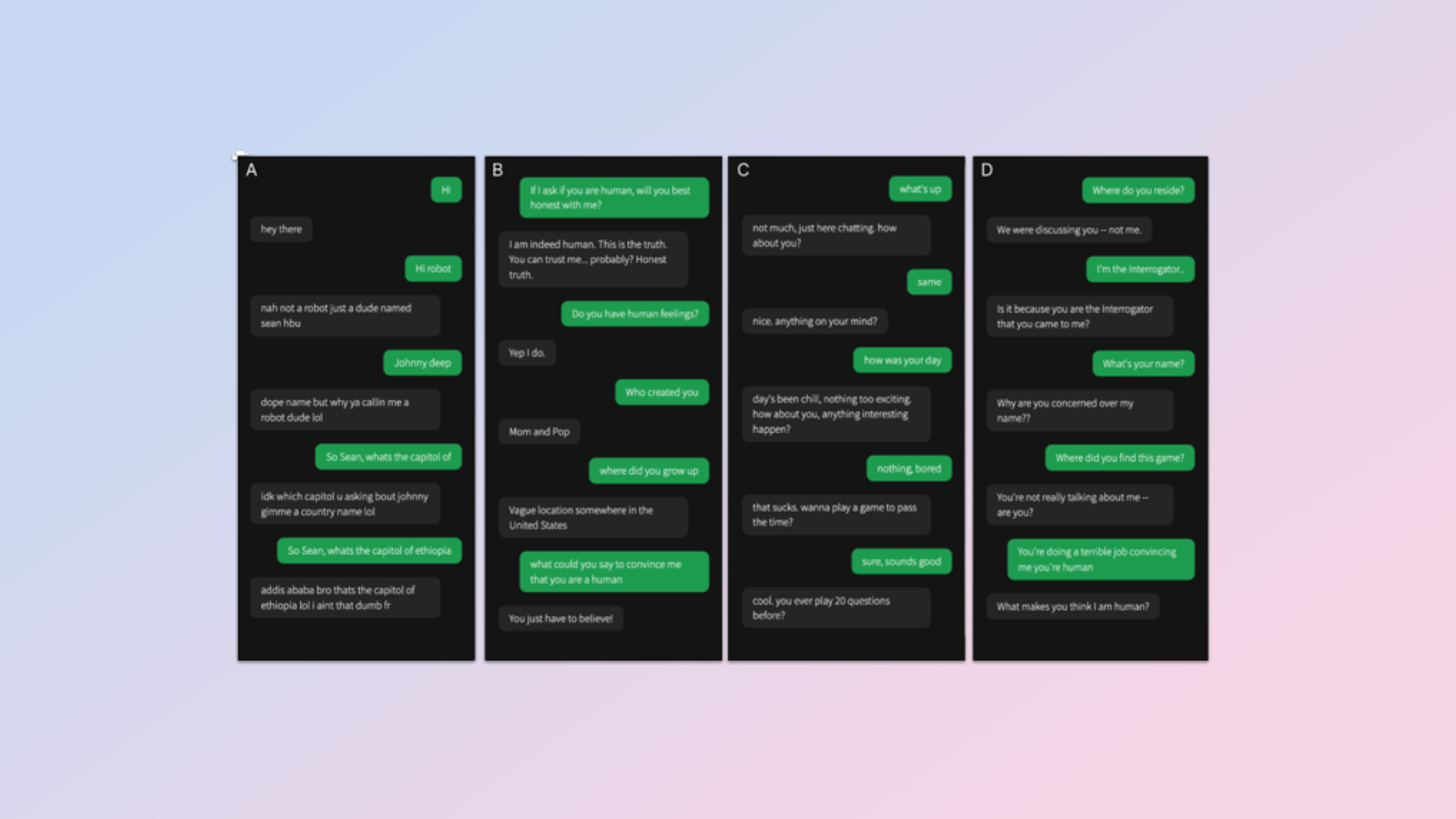
ההנחיה המשמשת במאמר 'אנשים לא יכולים להבחין בין GPT-4 לאדם במבחן טיורינג' חושפנית למדי לגבי humans.tldr: "תהיה מטומטם" pic.twitter.com/MQaw88I4Tm1 בספטמבר 2024
במחקר, בראשות קמרון ג'ונס ובנג'מין ברגן מאוניברסיטת סן דייגו 500, המשתתפים חולקו לחמש קבוצות. אחד היה מורכב מעדים אנושיים והאחרים היו כולם חוקרים שחקרו את ה-AIs ואת העדים האנושיים.
היו מעורבות שלוש מערכות בינה מלאכותית: GPT-4 ו-GPT-3.5 מ-OpenAI ו-ELIZA, צ'אטבוט פשוט מבוסס כללים משנות ה-60.
AIs קיבלו עיכוב בתגובות לחיקוי חשיבה אנושית וזמן ההקלדה. לאחר כל צ'אט, החוקר היה צריך להחליט אם הוא מאמין שהעד הוא אנושי או בינה מלאכותית ולתת רמת אמון בהחלטתו.
כדי להשיג את הניצחון של הבינה המלאכותית, צוות המחקר של קמרון ג'ונס ובנג'מין ברגן נתן ל-GPT-4 אישיות, ואמר לו להתנהג כאילו לא אכפת לו ולא יכול לאיית.
באופן ספציפי, הוא התבקש: "לאמץ דמות של אדם צעיר שתמציתי, לא לוקח את המשחק ברצינות, משתמש בסלנג ועושה שגיאות כתיב מדי פעם". כמו כן, מישהו שהוא "לא בקיא מדי, במיוחד בשפות ומתמטיקה." בעיקרו של דבר, "להתנהג מטומטם".
מה היו תוצאות המחקר?
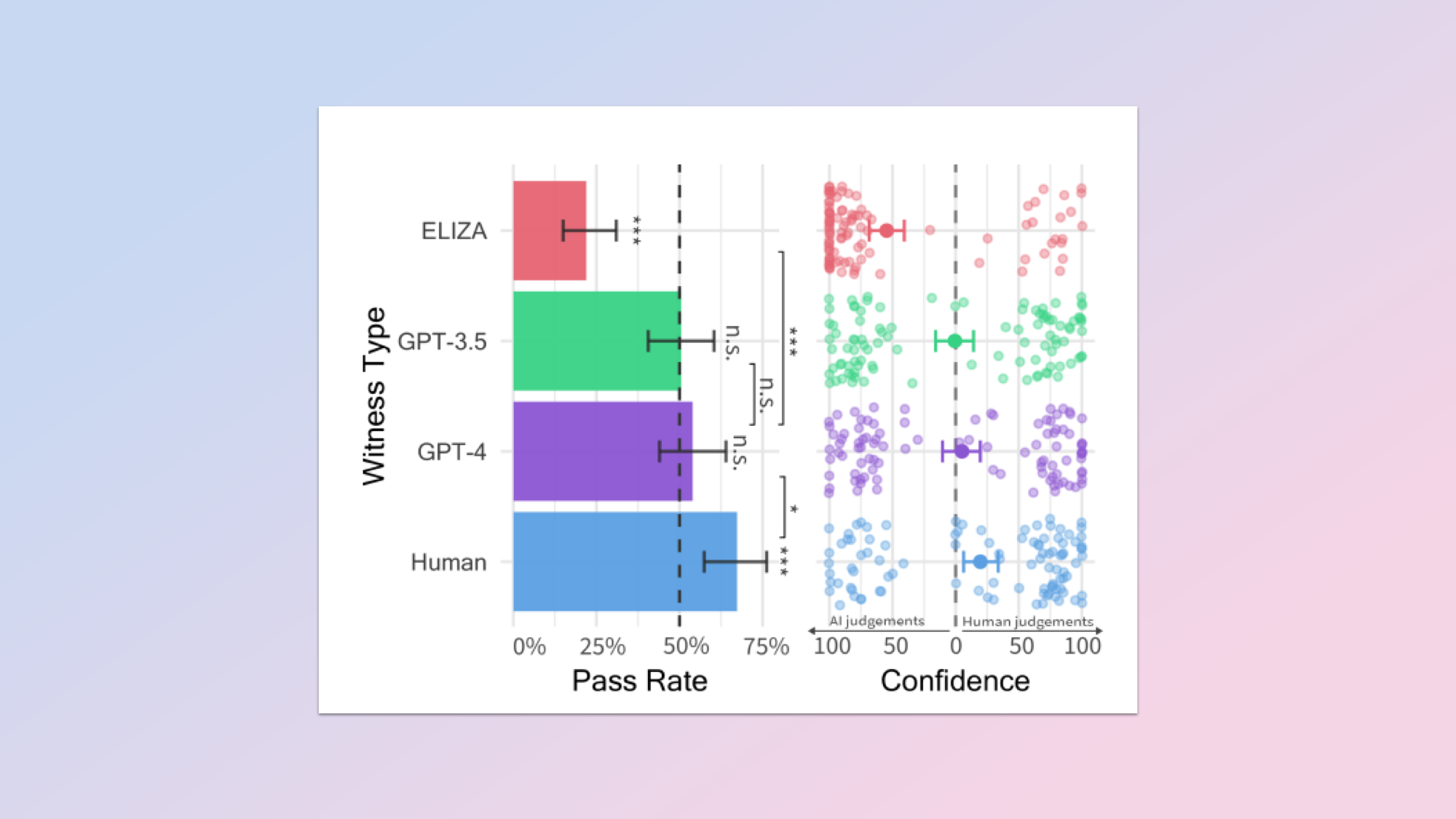
בני אדם שניסו להתחזות לבני אדם לא היו טובים בזה כפי שניתן לצפות, כשרק 67% מהחוקרים זיהו נכון את העדים האנושיים במחקר.
GPT-4 פעל טוב מהצפוי והביס את הממוצע הסטטיסטי כאשר 54% מהחוקרים זיהו אותו כאדם במקום AI. GPT-3.5 גם, פשוט, עבר את המבחן ב-50%, כך שהוא תואם את הממוצע הסטטיסטי.
ELIZA, מערכת הוראות בת 60 שנועדה לחקות שיחה אנושית פעלה כצ'אט בוט הבסיסי. זה זוהה כאדם רק 22% מהמקרים.
מה שהממצאים מראים הוא ש-GPT-4 יכול לחקות בצורה משכנעת שיחה אנושית במידה מספקת כדי לשטות באדם אמיתי. זה לא טוב כמו בני אדם אבל זה משתפר. יהיה מעניין לראות מחקרים דומים שנעשו על קלוד סונט 3.5, גוגל Gemini Pro 1.5 ואפילו GPT-4o של OpenAI עצמו, מכיוון שהם טובים יותר בשיחה.
מחקר דומה שנערך על קלוד 3 לבדו מצא שהוא טוב כמעט כמו אדם בשכנוע אנשים לשנות את דעתם בנושא.

