

במחקר שפורסם לאחרונה בכתב העת טֶבַע, חוקרים פיתחו והעריכו את מודל הפתולוגיה של Providence Gigapixel (Prov-GigaPath), מודל בסיס פתולוגי של שקף שלם, כדי להשיג ביצועים מתקדמים במשימות פתולוגיה דיגיטליות תוך שימוש בנתונים בעולם האמיתי ובארכיטקטורת שנאי ראייה חדשנית. .
לימוד: מודל בסיס שלם לפתולוגיה דיגיטלית מנתונים מהעולם האמיתי. קרדיט תמונה: Color4260 / Shutterstock
רקע כללי
פתולוגיה חישובית יכולה לחולל מהפכה באבחון סרטן באמצעות יישומי תת-טיפוס, בימוי וחיזוי פרוגנוסטי. עם זאת, שיטות נוכחיות דורשות נתונים מוערים נרחבים, אשר יקרים וגוזלים זמן. למידה בפיקוח עצמי מראה הבטחה על ידי שימוש בנתונים לא מתויגים כדי להכשיר מודלים מראש, ומפחיתה את הצורך הזה. האתגרים כוללים את האיכות המוגבלת והמשתנה של הנתונים הזמינים, קושי ללכוד דפוסים מקומיים וגלובליים וגישה מוגבלת למודלים שהוכשרו מראש. מודלים של בסיס מספקים הכללה חזקה, שהיא חיונית לתחומים ביו-רפואיים עם נתונים בשפע ללא תווית. יש צורך במחקר נוסף כדי לשפר את יכולת ההכללה ואת הישימות הקלינית של מודלים אלה על פני מערכי נתונים מגוונים והגדרות בעולם האמיתי.
לגבי המחקר
העיבוד המקדים של המחקר הנוכחי של תמונות שקופיות שלמות (WSIs) כלל צינור ל-171,189 שקופיות מוכתמות המטוקסילין ואאוזין (H&E) ושקופיות אימונוהיסטוכימיה. פילוח רקמות סינן אזורי רקע באמצעות סף תמונת Otsu. גודל WSI שונה ל-0.5 מיקרומטר לפיקסל ונחתך לאריחים של 256×256 פיקסלים, תוך השלכת אריחים עם פחות מ-10% כיסוי רקמה. Prov-GigaPath הוכשר מראש עם הגדרות Vision Transformer (ViT) וזיקוק ידע ברשתות גרסה 2 (DINOv2) על 1,384,860,229 אריחים. מקודד השקופיות השתמש בארכיטקטורת Long Sequence Network (LongNet). אימון מקדים, הכולל דיסקרטיזציה של רשתות, הגדלות ומקודדים אוטומטיים ממוסכים, השתמש ב-16 צמתים עם 4×80 GB A100 GPUs, שהושלמו תוך יומיים.
Prov-GigaPath הושווה ל-hierarchical Image Pyramid Transformer (HIPT), מודל פתולוגיה מבוסס למידה קונטרסטית (CtransPath), והכללה חזקה ויעילה בנתונים של למידת מכונה בפיקוח עצמי להדמיה אבחנתית (REMEDIS). HIPT, שהוכשר מראש על שקופיות אטלס גנום הסרטן (TCGA), השתמש בארכיטקטורת שנאי פירמידת תמונה היררכית, בעוד ש-CtransPath שילב מודלים Convolutional Neural Network (CNN) ו-SwinTransformer. REMEDIS השתמש בעמוד שדרה של Resnet עם גישת Simple Framework for Contrastive Learning of Visual Representations (SimCLR). Prov-GigaPath והמודלים הללו כוונו היטב למשימות מגוונות במורד הזרם תוך שימוש בטכניקות של למידה מרובה מופעים מבוססי-תשומת לב (ABMIL) להטמעות ברמת שקופיות.
לצורך חיזוי מוטציות, נעשה שימוש בנתוני Providence Pathology (Prov-Path) לבניית משימות, כולל סמנים ביולוגיים של Pan-tumor Cancer (pan-cancer) ומוטציות גנים, שהוערכו באמצעות Area Under the Receiver Operating Characteristic Curve (AUROC) ו- Area Under the Precision -עקומת היזכרות (AUPRC) באימות צולב פי 10. הערכות תת-הסוגים לסרטן כיסו תשעה סוגים, עם מודלים שהותאמו ל-20 תקופות.
יישור שפת ראייה כלל יצירת 17,383 צמדי דוחות WSI פתולוגיים, שעובדו עם בסיס הקוד הפתוח Contrastive Language-Image Pre-training (OpenCLIP). הדוחות נוקו באמצעות Generative Pre-trained Transformer (GPT)-3.5, והטבעות טקסט חושבו עם מודל ה-text-embedding-ada-002 של OpenAI. משימות חיזוי אפס העריכו מודלים כמו Multiple Instance Learning Zero-shot Transfer (MI-Zero), אימון קדם ביו-רפואי שפה-תמונה קונטרסטית (BiomedCLIP), ואימון מראש לשפה-תמונה ספציפית לפתולוגיה (PLIP) על תת-טיפוס ומוטציה חיזוי מצב, באמצעות הגדרות ותבניות הנחיות מ-MI-Zero.
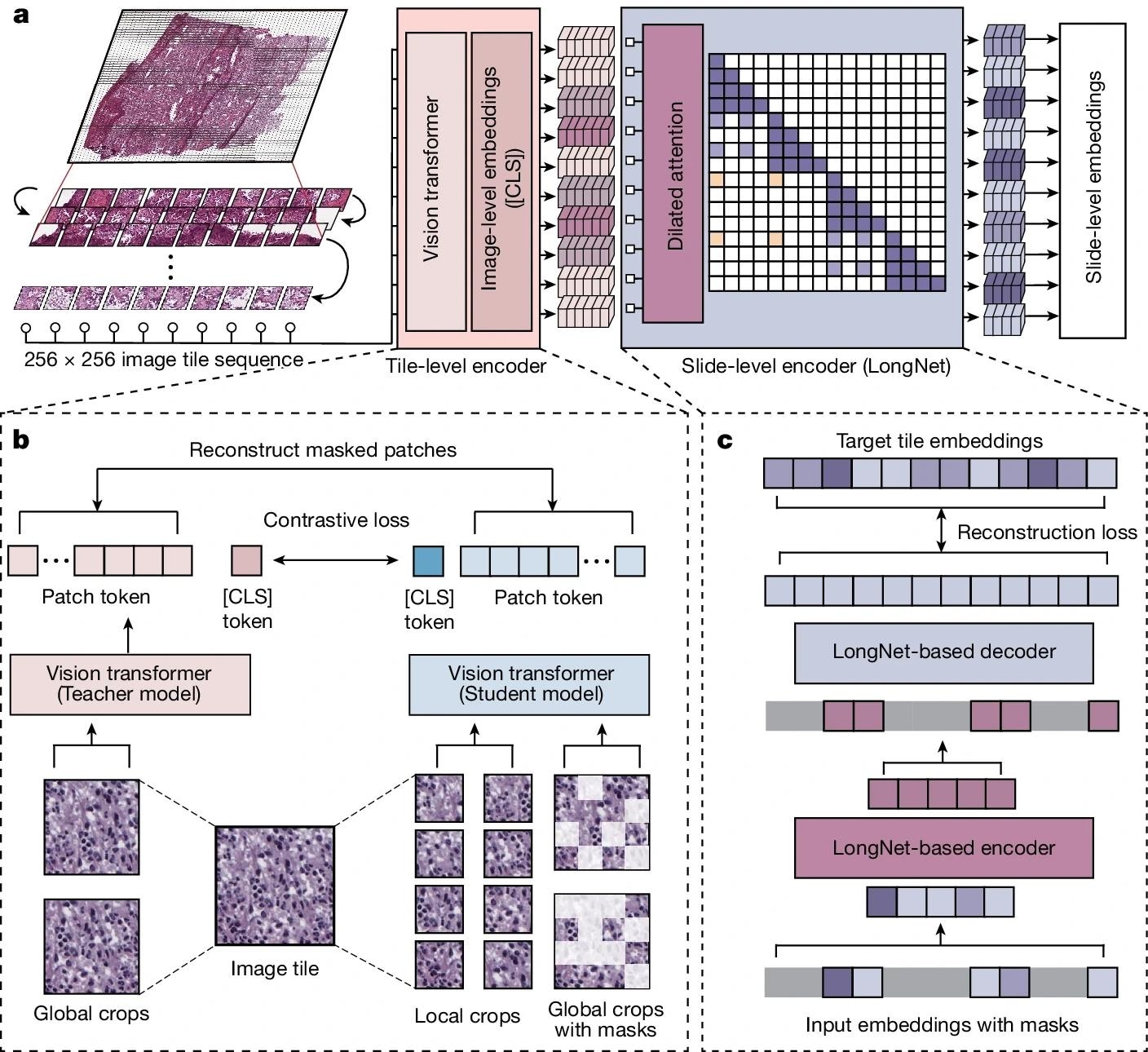
א, תרשים זרימה המציג את ארכיטקטורת המודל של Prov-GigaPath. Prov-GigaPath מסדרת תחילה כל קלט WSI לרצף של 256 × 256 אריחי תמונה בסדר ראשי ומשתמש במקודד ברמת אריחי תמונה כדי להמיר כל אריח תמונה להטבעה ויזואלית. לאחר מכן, Prov-GigaPath מיישם מקודד ברמת שקופיות המבוסס על ארכיטקטורת LongNet כדי ליצור הטמעות בקונטקסט, שיכולות לשמש בסיס ליישומים שונים במורד הזרם. באימון מקדים ברמת אריחי תמונה באמצעות DINOv2. ג, אימון מקדים ברמת שקופיות עם LongNet באמצעות מקודד אוטומטי במסווה. (CLS) הוא אסימון הסיווג.
תוצאות המחקר
המחקר הוכיח כי Prov-GigaPath משיגה ביצועים מעולים במשימות שונות של פתולוגיה דיגיטלית בהשוואה לשיטות הקיימות. Prov-GigaPath הוכשרה מראש על Prov-Path, מערך נתונים גדול שנגזר ממערכת הבריאות של Providence. מערך נתונים זה כולל 1,384,860,229 אריחי תמונה מתוך 171,189 שקופיות פתולוגיות שלמות מכ-30,000 מטופלים. המודל משתמש בארכיטקטורת GigaPath, וממנף את שיטת LongNet למידול בהקשר גדול במיוחד של Gigapixel WSIs.
Prov-GigaPath הדגים שיפורים משמעותיים בחיזוי מוטציות ובמשימות תת-טיפוס סרטן. לדוגמה, במשימת חיזוי של חמישה גנים ספציפית ל-Lung Adenocarcinoma (LUAD) תוך שימוש בנתוני TCGA, Prov-GigaPath גבר על מודלים מתחרים עם ציוני AUROC ו- AUPRC גבוהים יותר. תוצאות דומות נצפו במשימות חיזוי Pan-Cancer 18-biomarkers ובמשימות חיזוי Pan-Cance Tumor Mutation Burden (TMB), המציגות את החוסן וההכללה של המודל על פני מערכי נתונים שונים.
בנוסף לחיזוי המוטציות, Prov-GigaPath הצטיין במשימות תת-טיפוס סרטן, תוך ביצועים טובים יותר מהמודלים המתקדמים ביותר בתת-טיפוס של תשעה סוגי סרטן עיקריים. שיפורי הביצועים המשמעותיים מדגישים את האפקטיביות של שילוב הטמעות אריחים מקומיות עם מידע הקשרי גלובלי ברמת השקופיות באמצעות LongNet.
Prov-GigaPath חקרה גם עיבוד שפת ראייה על ידי יישור תמונות פתולוגיות עם דוחות טקסטואליים קשורים. המודל השיג את תוצאות הסיווג הטובות ביותר של זריקת אפס במשימות תת-טיפוס של סרטן ריאות מסוג Non-Small Cell Lung Cancer (NSCLC) ו-Colorectal Adenocarcinoma (COADREAD), בהשוואה לשלושה מודלים פתולוגיים חדישים של ראייה-שפה. זה מצביע על היתרון של יישור ברמת השקופיות המופעל על ידי LongNet, תוך מינוף נתונים קליניים בעולם האמיתי על פני מקורות נתונים אחרים כמו טוויטר (X).
מסקנות
המחקר הדגיש את הפוטנציאל של Prov-GigaPath לשפר את האבחון הקליני ותמיכה בהחלטות בפתולוגיה דיגיטלית. המדרגיות וההתאמה שלו הופכות אותו לכלי מבטיח ליישומים ביו-רפואיים רחבים יותר, המאפשרים למידה יעילה בפיקוח עצמי מתמונות ברזולוציה גבוהה. Prov-Path כולל 1,384,860,229 אריחי תמונה מתוך 171,189 שקופיות פתולוגיות של כ-30,000 מטופלים, מה שהופך אותה לגדולה משמעותית מ-TCGA. GigaPath משתמש ב-LongNet5 עבור מודלים בהקשר גדול במיוחד של Gigapixel WSIs. Prov-GigaPath הדגימה ביצועים עדכניים בנושאי פתומיקה, תת-טיפוס סרטן ומשימות עיבוד שפת ראייה ב-Providence וגם ב-TCGA. הצלחת המודל מעידה על יישומו לתחומים ביו-רפואיים רחבים יותר ללמידה יעילה בפיקוח עצמי מתמונות ברזולוציה גבוהה.

