

במחקר שפורסם לאחרונה ב- כתב עת בינלאומי ליושרה חינוכית, חוקרים בסין השוו, לראשונה, את הדיוק של גלאי תוכן מבוססי בינה מלאכותית (AI) וסוקר אנושי בזיהוי מאמרים הקשורים לשיקום שנוצרו על ידי בינה מלאכותית, הן מקוריות והן בפרפראזה. הם גילו שבין הכלים שניתנו, Originality.ai זיהה 100% מהטקסטים שנוצרו בינה מלאכותית, סוקרים פרופסוריים זיהו במדויק לפחות 96% מהמאמרים שנוסחו מחדש בינה מלאכותית, וסוקר סטודנטים זיהו 76% מהמאמרים שנוסחו מחדש בבינה מלאכותית, והדגישו את היעילות של גלאי AI וסוקרות מנוסים.
מחקר: הבלשים הגדולים: בני אדם מול גלאי בינה מלאכותית בתפיסת כתיבה רפואית שנוצרה בשפה גדולה. קרדיט תמונה: ImageFlow / Shutterstock
רקע כללי
ChatGPT (קיצור של "Chat Generative Pretrained Transformer"), צ'אטבוט של מודל שפה גדול (LLM), נמצא בשימוש נרחב בתחומים שונים. ברפואה ובבריאות דיגיטלית, כלי בינה מלאכותית זה עשוי לשמש לביצוע משימות כגון הפקת סיכומי שחרור, סיוע באבחון ומתן מידע בריאותי. למרות התועלת שלו, מדענים מתנגדים להענקת סופר בפרסום אקדמי בשל חששות לגבי אחריות ומהימנות. תוכן שנוצר בינה מלאכותית עשוי להיות מטעה, ומחייב שיטות זיהוי חזקות. גלאי בינה מלאכותית קיימים, כמו Turnitin ו-Originality.ai, מראים הבטחה אך נאבקים בטקסטים עם פרפרזה ולעיתים קרובות מסווגים באופן שגוי מאמרים שנכתבו על ידי אדם. סוקרים אנושיים גם מפגינים דיוק מתון בזיהוי תוכן שנוצר בינה מלאכותית. מאמצים מתמשכים לשיפור זיהוי בינה מלאכותית ופיתוח הנחיות ספציפיות לתחום חיוניים לשמירה על היושרה האקדמית. כדי להתמודד עם הפער הזה, החוקרים במחקר הנוכחי שאפו לבחון את הדיוק של גלאי תוכן AI פופולרי בזיהוי מאמרים אקדמיים שנוצרו על ידי LLM ולהשוות אותם עם סוקרים אנושיים עם רמות מגוונות של הכשרת מחקר.
לגבי המחקר
במחקר הנוכחי, נבחרו 50 מאמרים שנבדקו עמיתים הקשורים לשיקום מתוך כתבי עת בעלי השפעה רבה. לאחר מכן נוצרו עבודות מחקר מלאכותיות באמצעות הנחיות ספציפיות בגרסה 3.5 של ChatGPT (המבקשים ממנו לחקות סופר אקדמי). המאמרים שהתקבלו נוסחו מחדש באמצעות Wordtune כדי לשפר את האותנטיות שלהם. בנוסף, נעשה שימוש בשישה גלאי תוכן מבוססי בינה מלאכותית כדי להבדיל בין מסמכים מקוריים, שנוצרו על ידי ChatGPT וניסוח מחדש של בינה מלאכותית. הכלים הכלולים היו בחינם לשימוש (GPTZero, ZeroGPT, Content at Scale, GPT-2 Output Detector) או בתשלום (Originality.ai וזיהוי כתיבה בינה מלאכותית של Turnitin). חשוב לציין, הגלאים לא ניתחו את קטעי השיטות והתוצאות של המסמכים. AI, תמיהה וציוני גניבה נקבעו לצורך ניתוח והשוואה. ניתוח סטטיסטי כלל שימוש במבחן שפירא-וילק, מבחן לבנה, ניתוח שונות וצמד ט-מִבְחָן.
בנוסף, ארבעה סוקרים אנושיים עיוורים, כולל שני סוקרים של סטודנטים ושני סוקרים פרופסוריים עם רקע בפיזיותרפיה ורמות הכשרה מחקריות שונות, קיבלו את המשימות של סקירה והבחנה בין מאמרים מקוריים למאמרים שנוסחו מחדש ב-AI. הסוקרים נבדקו גם להבין את ההיגיון מאחורי סיווג המאמרים שלהם.
תוצאות ודיון
הדיוק של גלאי תוכן בינה מלאכותית בזיהוי מאמרים שנוצרו בינה מלאכותית נמצאה כמשתנה. Originality.ai הראה דיוק של 100% בזיהוי מאמרים שנוצרו על ידי ChatGPT והן בניסוח מחדש של AI, בעוד ZeroGPT השיגה דיוק של 96% בזיהוי מאמרים שנוצרו באמצעות ChatGPT, עם רגישות של 98% וסגוליות של 92%. יתרה מכך, גלאי פלט GPT-2 ו-Turnitin הראו דיוק של 96% ו-94%, בהתאמה, עבור מאמרים שנוצרו באמצעות ChatGPT, אך הדיוק של Turnitin ירד ל-30% עבור מאמרים שנוסחו מחדש ב-AI. GPTZero ותוכן בקנה מידה הראו דיוק נמוך יותר בזיהוי עיתונים שנוצרו באמצעות ChatGPT, כאשר תוכן בקנה מידה סיווג שגוי של 28% מהמאמרים המקוריים. מעניין לציין ש- Originality.ai היה הכלי היחיד שלא הקצה ציוני AI נמוכים יותר למאמרים מנוסחים בהשוואה למאמרים שנוצרו באמצעות ChatGPT.
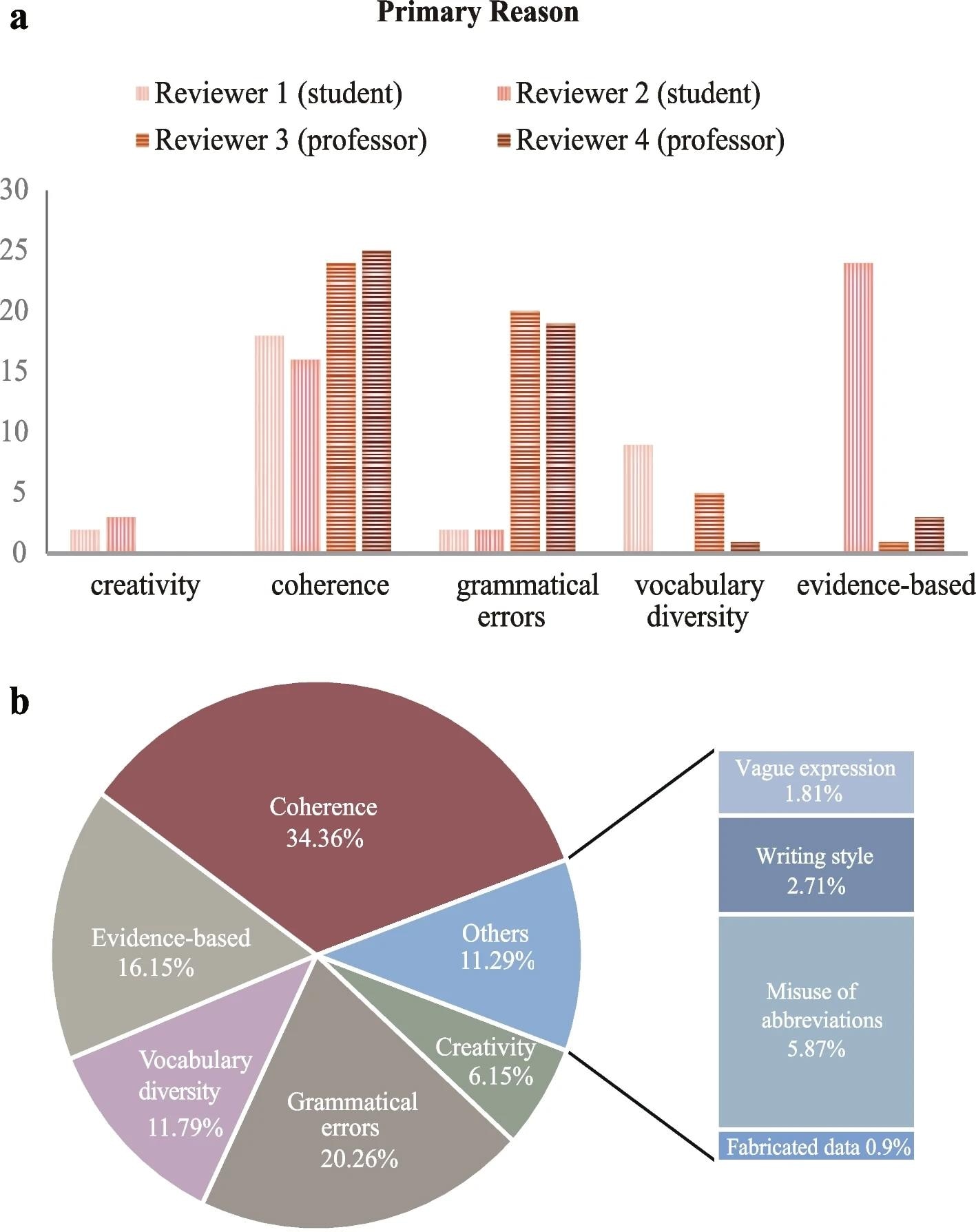 א התדירות של הסיבה העיקרית לכך שמאמרים מנוסחים מחדש על ידי בינה מלאכותית (AI) מזוהים על ידי כל סוקר. ב התדירות היחסית של כל סיבה לזיהוי מאמרים המנוסחים מחדש בינה מלאכותית (בהתבסס על שלוש הסיבות המובילות שניתנו על ידי ארבעת הסוקרים)
א התדירות של הסיבה העיקרית לכך שמאמרים מנוסחים מחדש על ידי בינה מלאכותית (AI) מזוהים על ידי כל סוקר. ב התדירות היחסית של כל סיבה לזיהוי מאמרים המנוסחים מחדש בינה מלאכותית (בהתבסס על שלוש הסיבות המובילות שניתנו על ידי ארבעת הסוקרים)
בניתוח הסוקרים האנושיים, הזמן החציוני שלוקח לארבעת הסוקרים להבחין בין מאמרים מקוריים למאמרים שנוסחו מחדש ב-AI היה 5 דקות ו-45 שניות. שיעורי דיוק גבוהים של 96% ו-100% נצפו במאמרי הבינה הבינה של שני הסוקרים הפרופסורים, למרות שהם סיווגו באופן שגוי 12% מהמאמרים שנכתבו על ידי אדם כמנוסחים מחדש בבינה מלאכותית. מצד שני, מבקרים סטודנטים יכלו להשיג רק 76% דיוק בזיהוי מאמרים בניסוח מחדש של AI. הסיבות העיקריות לזיהוי מאמרים כמנוסחים מחדש בינה מלאכותית נמצאו חוסר קוהרנטיות (34.36%), שגיאות דקדוקיות (20.26%) וטענות לא מבוססות ראיות מספיקות (16.5%), ולאחר מכן גיוון באוצר המילים, שימוש לרעה בקיצורים, יצירתיות , סגנון כתיבה, הבעה מעורפלת ונתונים סותרים. נצפתה הסכמה בין-דירוג בין סוקרים פרופסוריים, המדגימה הסכמה כמעט מושלמת בתגובות בינאריות והסכמה הוגנת בזיהוי סיבות ראשוניות ומשניות.
יתר על כן, Turnitin הראה ציונים נמוכים משמעותית של גניבה עבור מאמרים שנוצרו על ידי ChatGPT ומנוסחים מחדש ב-AI בהשוואה למאמרים המקוריים. הציונים או הערכות הבודקים בין מאמרים מקוריים שפורסמו לפני ואחרי השקת GPT-3.5-Turbo לא נמצאו שונים באופן משמעותי.
המחקר הנוכחי הוא הראשון שמספק תובנות חשובות ובזמן לגבי יכולתם של גלאי בינה מלאכותית וסוקרות אנושיות לזהות טקסט מדעי שנוצר בינה מלאכותית, הן מקוריות והן בפרפרזה. עם זאת, הממצאים מוגבלים על ידי השימוש ב-ChatGPT-3.5 (גרסה ישנה יותר), הכללה הפוטנציאלית של מאמרים מקוריים בעזרת AI ומספר קטן של סוקרים. נדרש מחקר נוסף כדי להתמודד עם אילוצים אלו ולשפר את יכולת ההכללה בתחומים שונים.
סיכום
לסיכום, המחקר מאמת את יעילותה של מערכת הביקורת עמית בהפחתת הסיכון לפרסום תוכן רפואי שנוצר בינה מלאכותית, ומציע את Originality.ai ו-ZeroGPT ככלי סינון ראשוני שימושיים. זה מדגיש את המגבלות של ChatGPT וקורא לשיפור מתמשך בזיהוי AI, תוך שימת דגש על הצורך להסדיר את השימוש ב-AI בכתיבה רפואית כדי לשמור על שלמות מדעית.

