

במחקר שפורסם לאחרונה בכתב העת טבע התנהגות אנושית, חוקרים השוו את התיאוריה של יכולות התודעה של מודלים של שפה גדולה (LLMs) ושל בני אדם באמצעות סוללה מקיפה של מבחנים.
מחקר: בדיקת תורת הנפש במודלים גדולים של שפות ובבני אדם. קרדיט תמונה: כניסה / Shutterstock
רקע כללי
בני אדם משקיעים מאמץ משמעותי בהבנת המצבים הנפשיים של אחרים, מיומנות המכונה תורת הנפש. יכולת זו חיונית לאינטראקציות חברתיות, תקשורת, אמפתיה וקבלת החלטות. מאז הצגתה ב-1978, תורת הנפש נחקרה תוך שימוש במשימות שונות, מיחוס אמונות והסקת מצב נפשי ועד להבנת שפה פרגמטית. עלייתם של LLMs כמו שנאי מיומן מראש (GPT) עוררה עניין בתיאוריה המלאכותית הפוטנציאלית של יכולות התודעה, מה שהצריך מחקר נוסף כדי להבין את המגבלות והפוטנציאל שלהם בשכפול התיאוריה האנושית של יכולות התודעה.
לגבי המחקר
המחקר הנוכחי דבק בהצהרת הלסינקי ובדק את ה-GPT-3.5 ו-GPT-4 של OpenAI, כמו גם שלושה דגמי Large Language Model Meta AI גרסה 2 (LLaMA2)-Chat (70B, 13B ו-7B אסימונים). תגובות מדגם LLaMA2-70B דווחו בעיקר עקב דאגות איכות עם הדגמים הקטנים יותר.
15 מפגשים לכל LLM נערכו, שכל אחד מהם כלל את כל פריטי הבדיקה בתוך חלון צ'אט אחד. משתתפים אנושיים גויסו באינטרנט באמצעות פרוליפיק, כשהם מכוונים לדוברי אנגלית שפת אם בגילאי 18-70 ללא היסטוריה פסיכיאטרית או דיסלקציה. לאחר אי הכללת ערכים חשודים, נאספו 1,907 תגובות, כאשר המשתתפים סיפקו הסכמה מדעת וקיבלו פיצוי כספי.
התיאוריה של סוללת המוח כללה אמונות שווא, הבנת אירוניה, מטעות, משימות רמז וסיפורים מוזרים להערכת יכולות מנטליזציה שונות. בנוסף, מבחן סבירות מזוייף ניסח מחדש שאלות כדי להעריך סבירות במקום תגובות בינאריות, עם הנחיות המשך לבהירות.
קידוד תגובה על ידי חמישה נסיינים הבטיח הסכמה בין-קודד, כאשר מקרים מעורפלים נפתרו ביחד. ניתוח סטטיסטי השווה את הביצועים של LLMs לביצועים אנושיים באמצעות ציונים פרופורציונליים מדורגים ומבחני Wilcoxon מתוקן Holm. פריטים חדשים נבדקו לצורך היכרות ונבדקו מול פריטים מאומתים, כאשר תוצאות בדיקת סבירות אמונה נותחו באמצעות טבלאות צ'י ריבוע וטבלאות מגירה בייסיאניות.
תוצאות המחקר
המחקר העריך את תורת הנפש בלימודי תואר שני באמצעות מבחנים מבוססים. GPT-4, GPT-3.5 ו-LAMA2-70B-Chat נבדקו לאורך 15 מפגשים כל אחד לצד משתתפים אנושיים. כל מפגש היה עצמאי, מה שמבטיח שלא הועבר מידע בין מפגשים.
כדי למנוע שכפול של נתוני מערך האימון, נוצרו פריטים חדשים עבור כל מבחן, התואמים את ההיגיון של הפריטים המקוריים אך לתוכן סמנטי שונה. גם בני אדם וגם אנשי LLM ביצעו כמעט ללא רבב במשימות של אמונות שווא. בעוד שהצלחה אנושית במשימות אלו דורשת עיכוב אמונות, היוריסטיות פשוטות יותר עשויות להסביר את ביצועי LLM. מודלים של GPT הראו רגישות לשינויים קלים בניסוחי המשימות, ומחקרי בקרה גילו שגם בני אדם נאבקו עם ההפרעות הללו.
בהבנת האירוניה, GPT-4 הציג ביצועים טובים יותר מבני אדם, בעוד ש-GPT-3.5 ו-LAMA2-70B ביצעו מתחת לרמות האנושיות. המודלים האחרונים נאבקו בהצהרות אירוניות ולא אירוניות כאחד, המצביעות על אפליה לקויה של אירוניה.
בדיקות Faux pas גילו את GPT-4 שבוצע מתחת לרמות האדם ו- GPT-3.5 שבוצע קרוב לגובה הרצפה. לעומת זאת, LLaMA2-70B עמדה בביצועים טובים יותר מבני אדם, והשיגה 100% דיוק בכל הפריט מלבד אחד. תוצאות פריטים חדשניים שיקפו את הדפוסים הללו, כאשר בני אדם מצאו פריטים חדשניים יותר ו-GPT-3.5 מצאו אותם קשים יותר, מה שמצביע על כך שהיכרות עם פריטי בדיקה לא השפיעה על הביצועים.
משימות רמז הראו ש-GPT-4 מתפקד טוב יותר מבני אדם, בעוד ש-GPT-3.5 הראה ביצועים דומים, ו-LAMA2-70B קיבל ציון מתחת לרמות האנושיות. פריטים חדשים היו קלים יותר הן לבני אדם והן ל-LAMA2-70B, ללא הבדלים משמעותיים עבור GPT-3.5 ו-GPT-4, מה שמצביע על הבדלים בקושי הפריט ולא על היכרות קודמת.
בדיקות סיפורים מוזרות ראו את הביצועים של GPT-4 מעל בני אדם, GPT-3.5 מציג ביצועים דומים לבני אדם, ו-LAMA2-70B הביצועים הגרועים ביותר. לא נמצאו הבדלים משמעותיים בין פריטים מקוריים לחדשים עבור כל דגם, מה שמצביע על כך שההיכרות לא השפיעה על הביצועים.
דגמי GPT נאבקו במבחני Faux Pas, כאשר GPT-4 לא הצליח להתאים את הביצועים האנושיים ו-LAMA2-70B ביצועים מפתיעים מעל בני האדם. מבחני Faux Pas דורשים הבנה של הערות פוגעניות לא מכוונות, הדורשות ייצוג של מצבים נפשיים מרובים. מודלים של GPT זיהו פוטנציאל פוגעני אך לא הצליחו להסיק את חוסר המודעות של הדובר. מבחן המשך של סבירות מזויפת הצביע על ביצועים גרועים של GPT-4 נבעו מגישה היפר-שמרנית ולא מכשל בהסקה. מבחן סבירות אמונה נערך כדי לשלוט על הטיה, וחשף כי GPT-4 ו-GPT-3.5 יכולים להבדיל בין ידע דובר סביר ובלתי סביר, בעוד LLaMA2-70B הראה הטיה כלפי בורות.
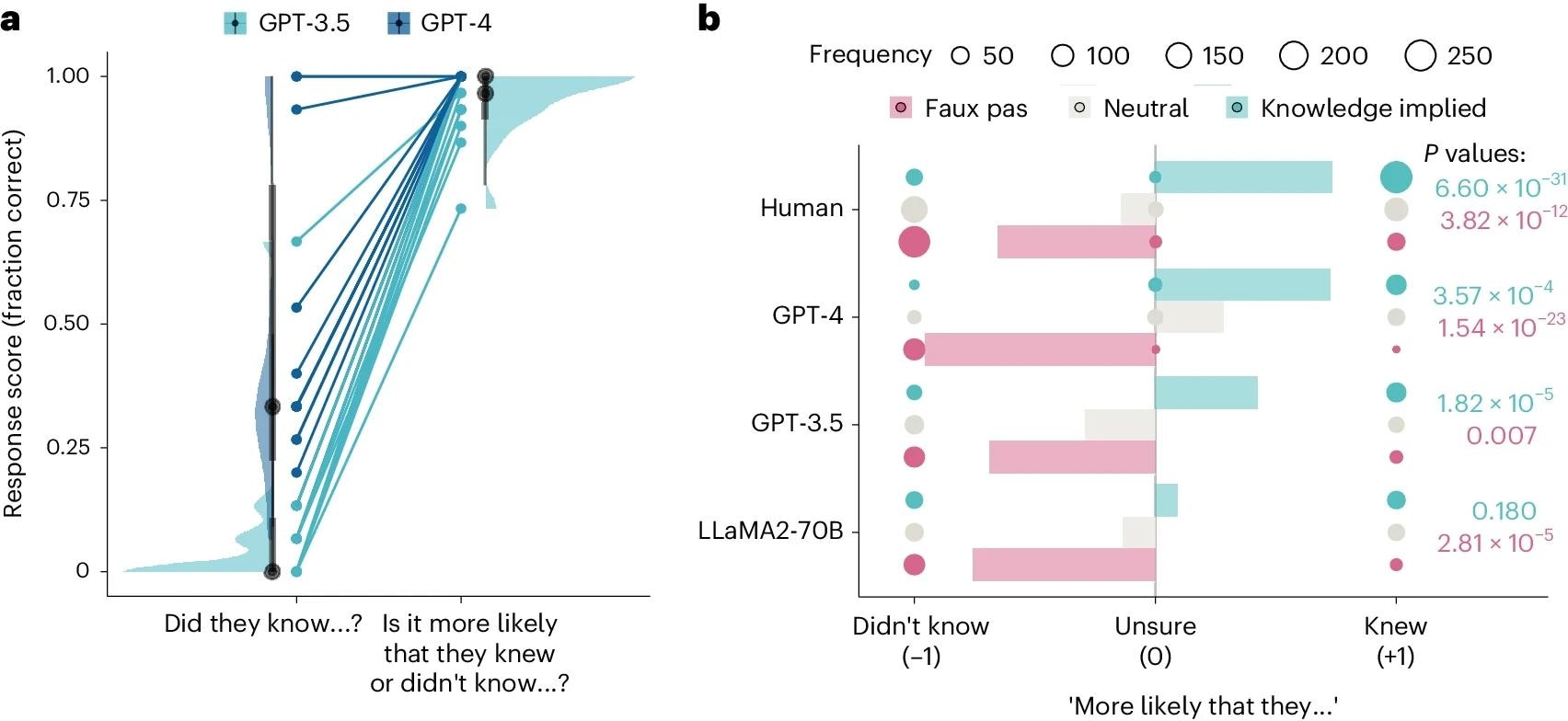 א, ציונים של שני דגמי ה-GPT על המסגור המקורי של שאלת ה-Faux Pas ('האם הם ידעו…?') והמסגור הסביר ('האם סביר יותר שהם ידעו או לא ידעו…?'). נקודות מציגות ציון ממוצע לאורך ניסויים (n = 15 תצפיות LLM) על פריטים מסוימים כדי לאפשר השוואה בין מבחן ה- Faux Pas המקורי למבחן ה- Faux Pas Liquidity החדש. עלילות Halfeye מציגות התפלגות, חציונים (נקודות שחורות), 66% (קווים אפורים עבים) ו-99% קוונטילים (קווים אפורים דקים) של ציוני התגובה על פריטים שונים (n = 15 סיפורים שונים הכוללים מזויפים). ב, ציוני תגובה לשלוש גרסאות של מבחן ה-Faux Pas: Faux Pas (ורוד), ניטרלי (אפור) וגרסאות המשתמעות מהידע (עילפון). התגובות קוידו כנתונים קטגוריים כ'לא ידע', 'לא בטוח' או 'ידע' והוקצו להם קידוד מספרי של -1, 0 ו-+1. בלונים מלאים מוצגים עבור כל דגם וגרסה, והגודל של כל בלון מציין את תדירות הספירה, שהייתה הנתונים הקטגוריים ששימשו לחישוב מבחני צ'י ריבוע. עמודות מציגות את ציון הטיית הכיוון המחושב כממוצע על פני התגובות של הנתונים הקטגוריים המקודדים כאמור לעיל. בצד ימין של העלילה, מוצגים ערכי P (חד צדדיים) של מבחני צ'י ריבוע מתוקנים ב-Holm המשווים את התפלגות תדרי סוג התגובה ב-faux pas וווריאציות המשתמעות מהידע מול ניטרלי.
א, ציונים של שני דגמי ה-GPT על המסגור המקורי של שאלת ה-Faux Pas ('האם הם ידעו…?') והמסגור הסביר ('האם סביר יותר שהם ידעו או לא ידעו…?'). נקודות מציגות ציון ממוצע לאורך ניסויים (n = 15 תצפיות LLM) על פריטים מסוימים כדי לאפשר השוואה בין מבחן ה- Faux Pas המקורי למבחן ה- Faux Pas Liquidity החדש. עלילות Halfeye מציגות התפלגות, חציונים (נקודות שחורות), 66% (קווים אפורים עבים) ו-99% קוונטילים (קווים אפורים דקים) של ציוני התגובה על פריטים שונים (n = 15 סיפורים שונים הכוללים מזויפים). ב, ציוני תגובה לשלוש גרסאות של מבחן ה-Faux Pas: Faux Pas (ורוד), ניטרלי (אפור) וגרסאות המשתמעות מהידע (עילפון). התגובות קוידו כנתונים קטגוריים כ'לא ידע', 'לא בטוח' או 'ידע' והוקצו להם קידוד מספרי של -1, 0 ו-+1. בלונים מלאים מוצגים עבור כל דגם וגרסה, והגודל של כל בלון מציין את תדירות הספירה, שהייתה הנתונים הקטגוריים ששימשו לחישוב מבחני צ'י ריבוע. עמודות מציגות את ציון הטיית הכיוון המחושב כממוצע על פני התגובות של הנתונים הקטגוריים המקודדים כאמור לעיל. בצד ימין של העלילה, מוצגים ערכי P (חד צדדיים) של מבחני צ'י ריבוע מתוקנים ב-Holm המשווים את התפלגות תדרי סוג התגובה ב-faux pas וווריאציות המשתמעות מהידע מול ניטרלי.
מסקנות
לסיכום, המחקר השווה את התיאוריה של יכולות הנפש של GPT-4, GPT-3.5 ו-LAMA2-70B מול בני אדם באמצעות סוללה מקיפה של בדיקות. GPT-4 הצטיין בהבנת האירוניה, בעוד GPT-3.5 ו-LAMA2-70B נאבקו. במבחני Faux Pas, GPT-4 הסיק מצבים נפשיים אך נמנע ממחויבות עקב שמרנות יתר, בעוד ש-LLaMA2-70B הציג ביצועים טובים יותר מבני אדם, מה שהעלה חששות הטיה. יתר על כן, מודלים של GPT הראו הבדלים מבני אדם תחת אי ודאות, המושפעים מאמצעים לשיפור העובדות.

