

במחקר שפורסם לאחרונה בכתב העת PLOS בריאות דיגיטליתחוקרים העריכו והשוו את הידע הקליני ויכולות החשיבה האבחנתיות של מודלים של שפה גדולה (LLMs) עם אלו של מומחים אנושיים בתחום רפואת העיניים.
מחקר: מודלים לשוניים גדולים מתקרבים לידע קליני והנמקה ברמת מומחה ברפואת עיניים: מחקר חתך ראש בראש. קרדיט תמונה: ozrimoz / Shutterstock
רקע כללי
רובוטריקים מיומנים מראש (GPT), GPT-3.5 ו-GPT-4, הם מודלים מתקדמים של שפה שהוכשרו על מערכי נתונים נרחבים מבוססי אינטרנט. הם מחזקים את ChatGPT, בינה מלאכותית לשיחות (AI) הבולטת בהצלחת היישום הרפואי שלה. למרות דגמים מוקדמים יותר שנאבקו בבדיקות רפואיות מיוחדות, GPT-4 מציג התקדמות משמעותית. החששות נמשכים לגבי 'זיהום' הנתונים והרלוונטיות הקלינית של ציוני המבחנים. דרוש מחקר נוסף כדי לאמת את הישימות הקלינית והבטיחות של מודלים של שפה במסגרות רפואיות בעולם האמיתי ולטפל במגבלות הקיימות בידע המיוחד וביכולות החשיבה שלהם.
לגבי המחקר
שאלות לבחינת המלגה של המכללה המלכותית לרופאי עיניים (FRCOphth) חלק 2 נשאבו מספר לימוד מיוחד שאינו זמין באופן נרחב באינטרנט, מה שממזער את הסבירות ששאלות אלו יופיעו בנתוני ההכשרה של לימודי LLM. סה"כ חולצו 360 שאלות רב-ברירה המשתרעות על פני שישה פרקים, וקבוצה של 90 שאלות בודדה לבחינה מדומה ששימשה להשוואת ביצועים של תואר שני ורופאים. שני חוקרים יישרו את השאלות הללו עם הקטגוריות שצוינו על ידי ה-Royal College of Ophthalmologists, והם סיווגו כל שאלה לפי רמות הטקסונומיה של בלום של תהליכים קוגניטיביים. לא נכללו שאלות עם רכיבים שאינם טקסטואליים שאינם מתאימים לקלט LLM.
שאלות הבחינה הוכנסו לגרסאות של ChatGPT (GPT-3.5 ו-GPT-4) כדי לאסוף תשובות, תוך חזרה על התהליך עד שלוש פעמים לכל שאלה במידת הצורך. ברגע שדגמים אחרים כמו Bard ו- HuggingChat הפכו לזמינים, נערכו בדיקות דומות. התשובות הנכונות, כפי שהוגדרו בספר הלימוד, צוינו לשם השוואה.
חמישה רופאי עיניים מומחים, שלושה מתאמנים ברפואת עיניים ושני רופאים זוטרים כלליים השלימו באופן עצמאי את הבדיקה המדומה כדי להעריך את הישימות המעשית של המודלים. התשובות שלהם הושוו לאחר מכן מול תשובות ה-LLMs. לאחר הבחינה, רופאי עיניים אלה העריכו את תשובות ה-LLM באמצעות סולם Likert כדי לדרג את הדיוק והרלוונטיות, עיוורת לאיזה מודל סיפק איזו תשובה.
העיצוב הסטטיסטי של מחקר זה היה חזק מספיק כדי לזהות הבדלי ביצועים משמעותיים בין LLMs ורופאים אנושיים, במטרה לבדוק את השערת האפס ששניהם יפעלו באופן דומה. מבחנים סטטיסטיים שונים, לרבות מבחני צ'י בריבוע ו-t-זוגיים, יושמו כדי להשוות ביצועים ולהעריך את העקביות והאמינות של תגובות LLM מול תשובות אנושיות.
תוצאות המחקר
מתוך 360 שאלות הכלולות בספר הלימוד לבחינת FRCOphth חלק 2, 347 נבחרו לשימוש, כולל 87 מפרק הבחינה המדומה. ההחרגות כללו בעיקר שאלות עם תמונות או טבלאות, שלא היו מתאימות לקלט בממשקי LLM.
השוואות ביצועים גילו ש-GPT-4 עלה משמעותית על GPT-3.5, עם שיעור תשובה נכונה של 61.7% לעומת 48.41%. התקדמות זו ביכולות של GPT-4 הייתה עקבית בסוגים שונים של שאלות ונושאים, כפי שתואר על ידי המכללה המלכותית לרופאי עיניים. תוצאות מפורטות וניתוחים סטטיסטיים אישרו עוד יותר את הביצועים האיתנים של GPT-4, מה שהופך אותו לכלי תחרותי אפילו בקרב תואר שני ורופאים אנושיים, במיוחד רופאים זוטרים ומתאמנים.
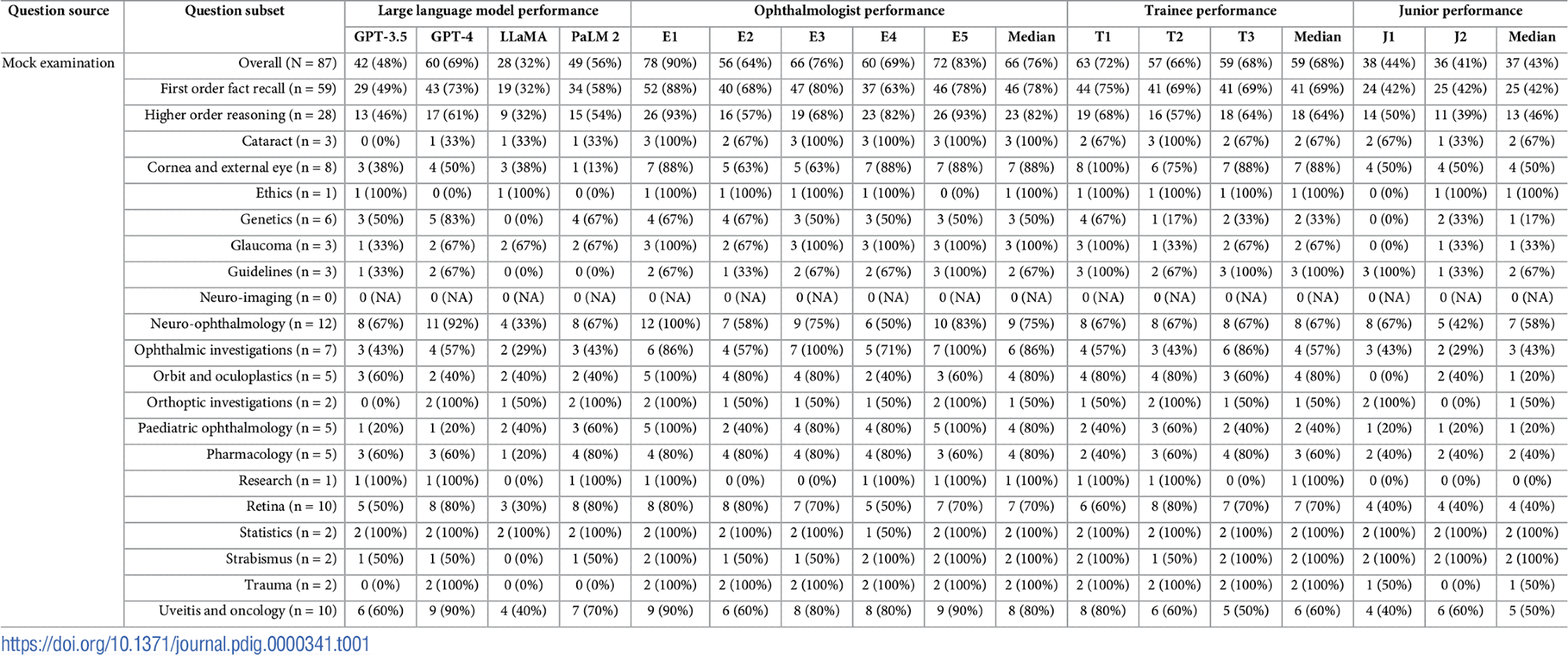 מאפייני בחינה ונתוני ביצועים פרטניים. התפלגויות נושא וסוג השאלות מוצגות לצד ציונים שהושגו על ידי LLMs (GPT-3.5, GPT-4, LLaMA ו-PaLM 2), רופאי עיניים מומחים (E1-E5), חניכי רפואת עיניים (T1-T3) ורופאים זוטרים לא מתמחים (J1- J2). ציונים חציוניים אינם מסתכמים בהכרח לציון החציוני הכולל, מכיוון שציונים שברים בלתי אפשריים.
מאפייני בחינה ונתוני ביצועים פרטניים. התפלגויות נושא וסוג השאלות מוצגות לצד ציונים שהושגו על ידי LLMs (GPT-3.5, GPT-4, LLaMA ו-PaLM 2), רופאי עיניים מומחים (E1-E5), חניכי רפואת עיניים (T1-T3) ורופאים זוטרים לא מתמחים (J1- J2). ציונים חציוניים אינם מסתכמים בהכרח לציון החציוני הכולל, מכיוון שציונים שברים בלתי אפשריים.
בבדיקת המדומה המותאמת במיוחד בת 87 שאלות, GPT-4 לא רק הוביל בין ה-LLMs אלא גם קיבל ציונים בהשוואה לרופאי עיניים מומחים וטובים משמעותית מרופאים זוטרים ומתלמדים. הביצועים בקבוצות המשתתפים השונות המחישו כי בעוד שרופאי העיניים המומחים שמרו על הדיוק הגבוה ביותר, החניכים התקרבו לרמות אלו, על פני הרופאים הזוטרים שאינם מתמחים ברפואת עיניים.
מבחנים סטטיסטיים גם הדגישו שההסכמה בין התשובות שסופקו על ידי תלמידי LLM שונים ומשתתפים אנושיים הייתה בדרך כלל נמוכה עד בינונית, מה שמעיד על שונות בהיגיון וביישום הידע בין הקבוצות. זה היה ברור במיוחד כאשר השוו את ההבדלים בידע בין המודלים לרופאים אנושיים.
בחינה מפורטת של השאלות המדומה מול תקני בדיקה אמיתיים הצביעו על כך שההגדרה המדומה שיקפה מקרוב את הבחינה הכתובה של FRCOphth חלק 2 בפועל ברמת הקושי והמבנה, כפי שהוסכם על ידי רופאי העיניים המעורבים. התאמה זו הבטיחה שההערכה של LLMs ותגובות אנושיות הייתה מבוססת בהקשר ריאליסטי ורלוונטי קלינית.
יתרה מכך, המשוב האיכותי מרופאי העיניים אישר העדפה חזקה של GPT-4 על פני GPT-3.5, בהתאמה לנתוני הביצועים הכמותיים. דירוגי הדיוק והרלוונטיות הגבוהים יותר עבור GPT-4 הדגישו את התועלת הפוטנציאלית שלו במסגרות קליניות, במיוחד ברפואת עיניים.
לבסוף, ניתוח של המקרים שבהם כל ה-LLMs לא הצליחו לספק את התשובה הנכונה לא הראה שום דפוס עקבי הקשור למורכבות או לנושא השאלות.

